At Motion, we have a very strong culture of not doing busy work.
This means every day I ask myself: "Do I really need to do this, or am I better off doing some high-value work?"
If the answer is "do more high-value work," then I ask myself: "Does this work still need to be done?"
If the answer is yes, then I ask myself: "Can an agent or workflow do it for me?"
Let's talk about how I automated user interview research, saving me (and my team) 5-10 minutes every time we meet with one of our users—and even more time setting up the calls.
Some background
We love meeting our users. In fact, each member of the product and design team meets with 3-5 users every week. We don't randomly choose the users we want to meet with—there's usually some criteria, something we want to learn about them.
I personally reach out to all users to maintain a human touch. Before an interview, I want to know: who they are, what they work on, and how they use Motion. So, I built 2 workflows.
Workflow 1: Schedule User Interviews
High Level Overview
- Take an Amplitude cohort
- Loop through each user
- Make sure I am allowed to reach out to them
- Make sure I have not recently reached out to them
- Pick a member of my team to do this user interview
- Draft a personalized email to this user asking them to meet with us
- Add a Motion booking link with the correct interviewer
- Send email to this user from my inbox
This one workflow saves me about 2 hours a week! (Sadly, it was very very hard to do 😞).
The Technical Implementation
- Trigger: A Slack message is sent to a specific channel
- Step 2: Check that it starts with the words: "Schedule user interviews"
- Step 3: Extract the Amplitude URL using Formatter by Zapier and check that it starts with a specific URL
- If it does match, proceed down Path A:

- Step 6: From the Amplitude URL, I extract the cohort ID and use it to call Amplitude's cohort API endpoint (hint: ChatGPT helped me figure out how to do this and properly format my tokens.)
- Step 7: Request CSV of the Cohort
- This takes some time to process. Technically, I should be polling the response URL to check if the request finished successfully, but since I know my cohorts are small, I just wait a minute and call it a day.
- Step 10: Use Formatter by Zapier to parse the CSV into a format Zapier understands.

- After parsing the CSV, I set up 2 counters:
- Step 11: This counter counts the total number of emails that are sent after deduping
- Step 12: This counter counts the total number of users in the cohort
- Step 13: This is annoying but must be done to properly reset all the counters and variables for this workflow
- Step 14: Now, I can finally start looping!

- Steps 15-19 are tedious but required for the loop to work properly:
- Step 15: Increments the loop counter. Ideally, this would be a simple variable I could reference (like "ParseCohortCSV.count"), but Zapier doesn't work that way.
- Step 16: Extracts the current user's email from the dataset. This feels redundant, but it's how Zapier handles data extraction in loops.
- Step 17: Deduplicates users I've already contacted. This step checks if the email already exists in my Zapier table—this is actually the most important step to avoid emailing the same user multiple times.
- Step 18: Only continues processing if the user hasn't been contacted before (i.e., if no record was found in Step 17).

- Step 20: Randomly selects an interviewer from my team and grabs their details—name, email, signature, and personal booking link.

- Step 21: Generates the user email. I created the prompt by giving ChatGPT 20 examples of my previous user emails to replicate my communication style.
- Step 22: Sends email to user.
- Step 23-25: These steps clean up my variables.
- Step 26: Lastly, I send a slack message to my team informing them of the cohort I contacted.


Some tips:
- Do NOT use Zapier's "Build in AI" Workflow. The first thing I did was give my workflow outline to Zapier's AI. It was not helpful at all.
- DO use ChatGPT/Claude as a copilot: ChatGPT o3 helped me build my zap from the outline I gave it. This was very helpful and I highly recommend this.
- DO ask ChatGPT first if something is not working. Be weary of hallucinations.
- DO give ChatGPT screenshots as hints when you get stuck. For example, if you don't know what to input into a field, take a screenshot and prompt ChatGPT.
Workflow 2: User Research
Now that the interviews are scheduled, I want to research each person beforehand—who they are, what they do, and how they use Motion.
High Level Overview
- Every morning at 6am, check the user interviews calendar and pull all scheduled interviews for that day.
- Look up each user's company and industry.
- Query Metabase to analyze their Motion usage: active tasks, projects, AI Meeting Notetaker activity, and document usage.
- Analyze the data and summarize it.
- Post the summary to our team Slack channel.
For this workflow, I used the same approach as before—I gave ChatGPT these bullet points and asked it to help me build the automation in n8n.
The Technical Implementation

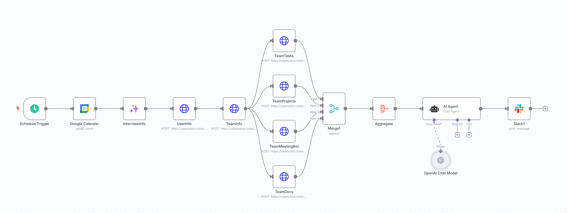
Daily Trigger: I scheduled the workflow to run every morning. Getting the timezone configuration right was trickier than expected.
- Step 1: Query Google Calendar to fetch the day's interview events. Filtering for "today only" also proved challenging—timezones are surprisingly complex to handle correctly.

- Step 2: Filter out Motion employees and select the first external attendee as the interviewee (I assume the first external attendee is the correct interviewee).
- Step 3: Pulls pre-meeting notes since Motion's booking system lets users add comments when scheduling—useful context for the user interview.
- Note: The parsing step was surprisingly intuitive—I described the logic in plain English and it converted to code. Ideally this would just be a prompt without the code step.

- Box 1: Custom Metabase Queries. These HTTP requests hit custom "questions" I created in Metabase to analyze how each user and their team uses tasks, projects, docs, and meetings.
- How n8n handles data flow: Each n8n node produces an array of outputs—for example, the UserInfo block might output 3 users if I'm meeting 3 people today, while the TeamTasks block might output 100 tasks from that team's recent activity. The key behavior is that each node runs once per input, so if UserInfo outputs 3 users, the next TeamInfo block will execute 3 separate times. This bulk processing is a nice feature since it's built into the platform itself.

- Box 2-3: The n8n Data Explosion Problem. This is where n8n gets tricky. Each node runs once per input, which creates exponential data growth.
- Example of the problem:
- Meeting 3 users today
- Each user has 100 tasks, 10 projects, 50 docs, 25 meetings
- Running nodes in series creates a cascade: Users (3) --> TeamInfo (3) --> Tasks (300) --> Projects (3,000) --> Meetings (75,000) --> Docs (3,750,000)
- This would run the AI block 4 million times—definitely not what I want.
- Example of the problem:
- The Solution:
- Merge Block (Box 2): Combines all HTTP outputs into a single array
- Aggregate Block (Box 3): Formats the data into one object that I can pass to the AI step


Conclusion
The combination of these two workflows has made my dream come true: I want to spend my time and my team's time actually listening to and meeting with users. My ideal was simple: "I want to show up to work every day with user meetings already on my calendar, to know who my users are, and to make each of them feel special."
This achieves exactly that!
In a future post, I'll show you how Motion's AI Meeting Notetaker generates a custom Friday report summarizing all the week's user interviews—highlighting key themes and which sessions I should review.
Now, I really wish there was a tool that made creating these workflows much easier. Zapier and n8n are awesome tools (I also tried Lindy, Gumloop, and others), but they all require significant grit, determination, and technical know-how to build something this powerful.
In total, this entire flow took about 20-25 hours to build, which is simply way too long.




